It is sometimes convenient to write the individual processes as Y1(⋅) and Y2(⋅), respectively. Then the joint probability measure of [Y1(⋅),Y2(⋅)] can be written as, [Y1(⋅),Y2(⋅)]=[Y2(⋅)|Y1(⋅)][Y1(⋅)], where the notation [A|B] is used to represent the conditional probability of A given B, and [B] represents the marginal probability of B. The conditional probability in (1) is shorthand for [Y2(s):s∈D∣Y1(v):v∈D]. The book by Banerjee et al. (2015, p. 273) states that it is meaningless to talk about the joint distribution of Y2(s1)∣Y1(s1) and of Y2(s2)|Y1(s2) as building blocks for the conditional approach, with which we agree. It also goes on to say that this "reveals the impossibility of conditioning," with which we disagree and explain why below.
It is not just one or a few finite-dimensional distributions that define the conditional approach, it is all of them. Further, these finite-dimensional distributions are for the hidden processes Y1(⋅) and Y2(⋅) and not for noisy incomplete data that we notate as Z1={Z1(s1,i)} and Z2={Z2(s2,i)}. Banerjee et al. (2015, p. 273) go on to state that the conditional approach is flawed and that kriging is not possible. Cressie and Zammit-Mangion (2016) show that the conditional approach defined through (1) yields a well defined bivariate (Gaussian) process (Y1(⋅),Y2(⋅)), and they perform kriging on Y1(⋅) based on the data Z1 and Z2.
The construction of a bivariate spatial covariance function follows directly from specification of the conditional mean and conditional covariance functions, as follows:
E(Y2(s)∣Y1(⋅))=∫Db(s,v)Y1(v)dv;s∈D,cov(Y2(s),Y2(u)∣Y1(⋅))=C2∣1(s,u);s,u∈Rd.
These specifications are enough to establish the Kolmogorov consistency conditions and hence the existence of the bivariate spatial process referred to above. Further, the cross-covariance functions are easy to derive, and their formula in the p=2 case is as follows (Cressie and Zammit-Mangion, 2016):
C12(s,u)=cov(Y1(s),Y2(u))=cov(Y1(s),E(Y2(u)∣Y1(⋅)))=∫DC11(s,w)b(u,w)dw;s,u∈D.
Furthermore, the conditional approach can be modified easily for processes indexed on different spatial domains: {Y1(s):s∈D1} and {Y2(s):s∈D2}, for D1,D2∈Rd; see Cressie and Zammit-Mangion (2016).
A temperature-pressure dataset was used in Gneiting et al. (2010) and Apanasovich et al. (2012) to fit symmetric bivariate models. The flexibility of the conditional approach can be demonstrated on this dataset, and it seen that there is a pronounced asymmetry in the cross-covariance structure that is picked up by the conditional approach. The direction of the dependence is suggested on physical grounds: Higher temperatures cause air to rise and hence pressure to decrease. The data are available from the R package, RandomFields (Schlather et al., 2015), and they refer to “error fields,” namely the respective differences between 2-day forecasts and observations from monitoring stations in the Pacific Northwest of North America on December 18, 2003 at 4 p.m.
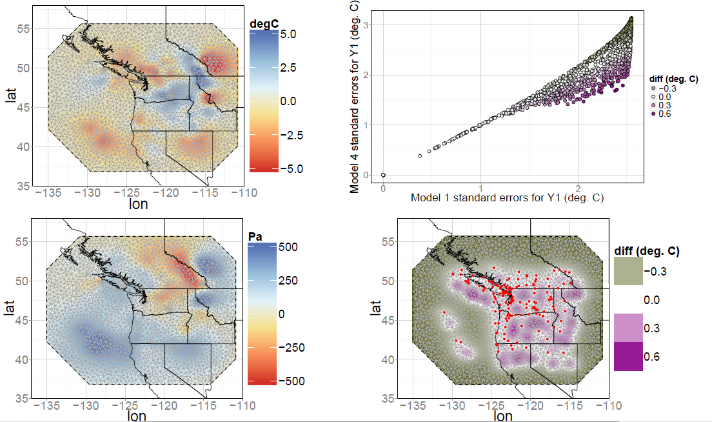
Figure 2: Left panels: The cokriged surface using maximum likelihood parameter estimates with an asymmetric model constructed using the conditional approach, for the temperature and pressure error fields. Top-right panel: A scatter plot of the kriging standard errors of Y1 (temperature) obtained with the asymmetric model against those obtained when assuming Y1 and Y2 are two independent Matérn fields (the independent Matérn model), at each of the mesh vertices. The colour illustrates the difference between the two, with green denoting the higher standard error of the asymmetric model and purple the higher standard error of the independent Matérn model. Bottom-right panel: A spatial plot of the difference in the kriging standard errors of Y1 (temperature) obtained with the asymmetric model and the independent Matérn model, with green denoting a higher standard error of the asymmetric model and purple a higher standard error of the independent Matérn model. The red dots denote the station locations.
